

BERT和GPT的区别:了解模型结构、预训练方法及应用领域
说在前面
在自然语言处理(NLP)的演变过程中,预训练语言模型已经成为推动技术进步的核心工具。其中,BERT和GPT是两个最具代表性的模型,它们在结构和应用方面有显著的区别。这篇文章将带您详细了解BERT和GPT的模型结构、预训练方法及应用领域,不论您是初学者还是经验丰富的AI从业者,本文都将帮助您全面掌握这两个重要的模型。
预期内容概述:
- 定义和基本概念
- 历史和发展
- 模型结构分析
- 预训练方法比较
- 应用领域探讨
- 相关Tips
- 常见问题解答

关键词 背景介绍
定义和基本概念
BERT(Bidirectional Encoder Representations from Transformers)是一种通过编码器–解码器的双向Transformer结构预训练的语言模型。其双向性使它能够从句子的上下文中学习词语之间的关系。GPT(Generative Pre-trained Transformer)则是一种自回归语言模型,通过前向的仅编码器的Transformer结构进行训练,专注于语言生成任务。
历史和发展
BERT由Google在2018年发布,其创新性主要在于引入了双向Transformer,并应用于多种NLP任务如问答系统和情感分析。GPT由OpenAI推出,其第一版GPT在2018年发布,随后在2019年和2020年相继发布了更为先进的GPT-2和GPT-3版本,推动了NLP模型在语言生成任务上的应用。
关键词 详细解读
模型结构分析
BERT和GPT的最主要区别在于它们的模型架构和数据处理方式。
BERT:双向Transformer
BERT采用Transformer的编码器部分,能够在预训练过程中同时考虑输入句子的左右上下文。这种语言表征可以捕捉到更多的信息,因此在理解任务(如问答和句子分类)中表现优异。
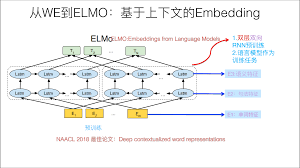
GPT:自回归Transformer
GPT则是使用Transformer的解码器部分进行单向(自回归)训练。编码器仅关注单向上下文(前文),从而主要适用于生成任务,如对话生成、文本续写。
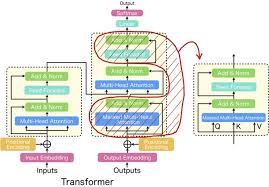
预训练方法比较
BERT:掩码语言模型(MLM)
BERT在预训练阶段使用了掩码语言模型(Masked Language Model)和下一句预测(Next Sentence Prediction)两种任务。MLM以随机方式屏蔽部分词语,并让模型预测这些词语来学习词间关系。NSP则帮助模型理解句子之间的关系。
GPT:自回归预训练
GPT的预训练采用自回归方法,即每次预训练时只预测下一个词。通过这种方式,GPT能够生成连贯的文本,这对文本生成任务尤为重要。由于不需要理解上下文过多的依赖关系,GPT对上下文文本生成有所限制,这就是其适用生成任务而非理解任务的原因。
应用领域探讨
BERT的应用领域
BERT的双向特性和使用掩码语言模型的预训练方式,使其在需要深度理解文本的任务中表现出色,例如:
- 问答系统(如QA系统)
- 情感分析
- 命名实体识别(NER)
- 文本分类
GPT的应用领域
GPT的自回归性质和在生成语言任务中的有效性,使其在生成类任务中占据主导地位,例如:
- 文本生成
- 对话系统
- 故事续写
- 自动写作辅助
关键词 相关Tips
- 选择合适的模型:根据具体任务需求选择BERT或GPT。如果任务需要深度的文本理解,优先考虑BERT;如果需要文本生成,GPT更为适用。
- 不断更新预训练模型:预训练模型不断发展,及时更新模型可以获得最佳的性能表现。例如,GPT-3引入了更大的参数量和改进的训练方式。
- 结合模型使用:在一些复杂任务中,结合使用BERT的理解能力和GPT的生成能力,可以取得更好的效果。
关键词 常见问题解答(FAQ)
什么是BERT和GPT的主要区别?
主要区别在于它们的模型架构和预训练方法。BERT采用双向Transformer结构,而GPT采用自回归Transformer结构。
BERT和GPT的适用场景有哪些?
BERT适用于需要理解文本的任务,如问答系统和情感分析;GPT适用于生成文本的任务,如自动写作和对话系统。
如何选择BERT或GPT模型?
根据具体需求来选择。如果任务需要深度理解文本内容,可以选择BERT;如果任务需要生成流利的文本,可以选择GPT。
总结
通过本文,我们详细比较了BERT和GPT这两个流行的预训练语言模型,探讨了它们的模型结构、预训练方法和应用领域的区别。BERT的双向Transformer结构使其在理解任务中表现出色,而GPT的自回归结构则使其在生成任务中具有优势。这些模型的选择应根据具体任务需求而定。未来,不断发展的预训练语言模型将持续推动NLP领域的进步,值得我们持续关注和深入研究。