

聊天机器人比较研究:GPT-3、ChatGPT免费在线版与其他AI智能机器人优势与选择
说在前面
当下,聊天机器人无疑是科技界的热门话题。从提升客户服务效率到丰富人们的日常对话,智能AI聊天机器人正在以飞快的速度改变我们的生活。鉴于此,本篇文章将深入探讨几大主流聊天机器人,包括GPT-3、ChatGPT免费在线版以及其他AI智能机器人,全面分析它们的优劣势,并提供选择指南。
了解这些机器人的异同不仅有助于个人用户选择合适的工具,对于企业来说,更是提升工作效率和优化客户体验的重要一步。本篇将分为几个部分,包括基础概念、详细解读、实用建议、常见问题解答等,以期为您提供全方位的认知与参考。
什么时候选择GPT-3?什么时候使用ChatGPT免费在线版?其他AI智能机器人又有什么独特之处?这些问题将在下文一一解答。
插图:
背景介绍
定义和基本概念
聊天机器人,又称对话机器人,是通过自然语言处理(NLP)技术与用户进行交互的计算机程序。它们可分为规则基础型和AI驱动型,后者由于具备机器学习能力,因此能够更好地理解和响应复杂的语句。
GPT-3(Generative Pre-trained Transformer 3)是由OpenAI开发的一种大型语言模型,具备生成类似人类语言的文本的能力。ChatGPT则是其衍生产品之一,专注于对话交互。
历史和发展
聊天机器人的概念可以追溯到1960年代的ELIZA,一个简单的对话程序。随着计算机科学的进步,尤其是自然语言处理技术的发展,现代聊天机器人变得越来越智能。2018年,OpenAI推出了GPT-3,它以超大规模和高度准确的语言生成能力震动了AI界。此后,基于此技术的ChatGPT应用广泛,免费在线版更是吸引了大量普通用户。
详细解读
GPT-3的优势与不足
GPT-3的最大优势在于其生成能力,可以根据输入生成高质量、流畅的文本。其应用场景广泛,包括自动完成文本、生成代码、翻译等。:
- 生成的文本高度自然,有时难以分辨是否由机器生成。
- 支持多种编程语言的代码生成和解释。
- 可以处理和生成多种语言的文本。
然而,GPT-3也有其不足之处:
- 高昂的计算成本,使得使用门槛较高。
- 偶尔可能生成不准确或不合适的内容。
- 处理实时数据和动态信息的能力有限。
插图:
ChatGPT 免费在线版
ChatGPT免费在线版基于GPT-3.5,专注于对话交互,以下是其主要特点:
- 使用免费,适合对价格敏感的用户。
- 对话自然流畅,增强用户互动体验。
- 适应各种对话场景,包括知识问答、情感交流等。
但也存在一些限制:
- 可能会有频繁的使用限制,如单次对话长度。
- 性能较付费版本有所压缩,处理复杂任务时可能较慢。
- 数据更新频率可能不如其他高端版本。
插图: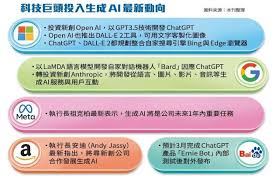
其他AI智能聊天机器人
目前市面上还有许多其他优秀的AI聊天机器人,如Google Bard、Microsoft的Bing AI等。它们各具特色:
- Google Bard:集成了Google的搜索引擎功能,具备强大的信息检索能力。
- Microsoft Bing AI:与Microsoft生态系统高度集成,支持多种微软工具的联动使用。
- Claude AI:由AI初创公司Anthropic推出,擅长人性化的对话体验。
这些机器人提供了各自独特的功能和优势,如更强的搜索能力、更流畅的多模式交互等。
实用建议
- 选型建议: 如果您需要高质量的文本生成,选择GPT-3是个不错的选择;如果希望进行日常对话,ChatGPT免费在线版更为适合。
- 综合考量: 在选择AI聊天机器人时,务必考虑使用场景、预算和具体需求。
- 定期更新: 使用免费的聊天机器人时,请留意更新和升级机会以获得更好的服务。
- 隐私保护: 注意使用AI聊天机器人的隐私政策,避免分享敏感信息。
- 多方测试: 可以同时尝试多个聊天机器人,比较其表现,找到最适合的工具。
常见问题解答(FAQ)
1. ChatGPT免费在线版和付费版有什么区别?
免费版通常在性能和数据更新频率上有所限制,适合基础对话任务。而付费版在响应速度、稳定性和数据更新频率上更有保证,适合对性能有较高要求的用户。
2. GPT-3如何实现高质量的文本生成?
GPT-3通过大型预训练数据集和深度学习技术来学习语言模式,能够生成类似人类的文本。其包含1750亿个参数,是迄今为止最大的一种语言模型之一。
3. 选择AI聊天机器人时应考虑哪些因素?
应考虑因素包括:预算、使用场景(如客户服务、内容生成、日常对话)、机器人回答的准确性和流畅度、使用的便利性及隐私保护政策等。
总结
通过本篇文章,我们详细探讨了几大主流AI聊天机器人,包括GPT-3、ChatGPT免费在线版和其他AI智能机器人。了解它们的优势与不足,可以帮助您根据具体需求做出最佳选择。重点是要明确自己的需求,并合理选择适合的工具。无论您是个人用户还是企业,正确使用AI聊天机器人的潜力都能极大提升您的日常效率和用户体验。
希望通过这篇详细的比较研究,您能对GPT-3、ChatGPT免费在线版以及其他AI智能聊天机器人有更清晰的认识,并做出明智的选择。未来,随着技术的不断进步,这些工具将变得更为强大和易用,值得我们持续关注和探索。