

如何利用Transformer优化GPT性能:处理长文本、生成文本及其变体详解
在前言部分,我们将简要介绍本文的主题,解释其重要性,并概述主要内容。
说在前面
人工智能(AI)和自然语言处理(NLP)的快速发展,让我们见证了从传统的浅层模型到深层神经网络模型的演进。其中,Transformer架构和基于它的语言模型GPT(Generative Pretrained Transformer)在处理和生成文本方面表现出极大的潜力和优势。那么,如何在具体应用中充分利用Transformer优化GPT性能呢?
本文将深入探讨这一主题,通过详解Transformer在处理长文本、生成文本方面的应用,分析其架构和变体在GPT中的作用。同时,我们还将提供相关的实用技巧和常见问题解答,帮助您更好地理解和应用这些技术。
关键词 背景介绍
定义和基本概念
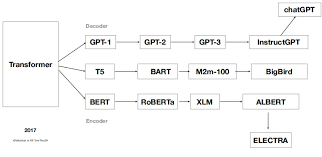
Transformer模型由Vaswani等人在2017年提出,其核心理念是自注意力机制(Self-Attention Mechanism)。相比于传统的序列模型(如RNN和LSTM),Transformer能更有效地捕捉长距离依赖关系,表现出了出色的效果。GPT是OpenAI推出的基于Transformer的生成式预训练模型,主要用于文本生成任务。GPT利用海量文本语料进行预训练,然后通过微调适应具体任务。
历史和发展
Transformer自从被提出后,迅速成为NLP领域的热点,并推动了一系列强大模型的诞生,如BERT、GPT、RoBERTa等。GPT模型的发展大致经历了三个阶段:GPT-1、GPT-2和GPT-3,随着模型参数和训练数据的不断增加,其生成文本的流畅性和上下文理解能力也逐步提高。
关键词 详细解读
Transformer架构解析
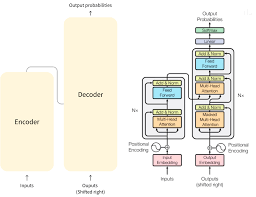
Transformer架构主要包括编码器(Encoder)和解码器(Decoder)两部分。编码器将输入序列映射到一个高维空间的表示,解码器则利用这些表示生成输出序列。每一层编码器和解码器主要由多头自注意力机制和前馈神经网络组成。
GPT:Transformer的应用
在GPT中,主要采用了Transformer的解码器部分。通过自回归方式(即依赖前面生成的输出),GPT逐词生成文本。其训练过程包括两个阶段:预训练和微调。在预训练阶段,模型通过预测下一个词的方式学习语料库中的语言模式;在微调阶段,模型在具体任务数据上进行再训练,以适应特定应用。
处理长文本
Transformer在处理长文本时由于其自注意力机制,使得每个单词能考虑到整个序列中的任意单词,克服了传统序列模型难以捕捉长距离依赖的缺点。进一步的优化方法如Transformer-XL、Longformers等,通过片段递归和注意力稀疏等技术,进一步提升了长文本处理能力。
生成文本
GPT在文本生成方面表现尤为突出。通过预训练和微调,GPT能生成连贯且具备上下文联系的文本。常见的生成任务包括对话生成、文章续写和文本翻译。GPT采用生成式架构,通过给定的引导词或句子,不断预测下一个词,直到生成完整段落。
关键词 相关Tips
- Tip 1:合理选择超参数 – 在训练Transformer或GPT模型时,选择合适的超参数(如学习率、批量大小)至关重要,可以通过网格搜索或贝叶斯优化进行调优。
- Tip 2:数据预处理 – 对训练数据进行清洗、去重和归一化处理,能显著提高模型的训练效果和生成文本的质量。
- Tip 3:使用预训练模型 – 大多数情况下,直接使用开源的预训练模型(如Hugging Face Transformers库提供的模型)进行微调,比从头开始训练要省时省力且效果更佳。
- Tip 4:启用混合精度训练 – 通过使用Tensor Cores进行混合精度训练,可大幅减少显存占用,并加快训练速度。
- Tip 5:充分利用工具库 – 利用现有的工具库如Hugging Face的Transformers库,可以简化模型的训练和应用流程,提升工作效率。
关键词 常见问题解答(FAQ)
- 问:如何应对Transformer模型的计算资源需求?
答:可以通过使用分布式训练、多GPU并行计算或混合精度训练来提升训练效率,降低单个设备的负担。
- 问:如何处理长文本生成中的上下文关系?
答:可以采用片段递归方法(如Transformer-XL),或使用更底层的架构优化(如Sparse Attention)来增强模型对长文本的处理能力。
- 问:在微调GPT时,如何选择训练数据?
答:训练数据应尽可能多样化且与目标任务相关,同时对数据进行预处理以确保质量和一致性。
- 问:如何评价生成文本的质量?
答:可以采用BLEU、ROUGE等评估指标,同时结合人工评估,观察文本的流畅性、连贯性和上下文相关性。
总结
通过本文的探讨,我们了解了如何利用Transformer优化GPT性能,尤其是在处理长文本和生成文本方面的应用。我们详细解析了Transformer的架构、GPT的训练过程及其在实际应用中的表现。同时提供的一些实用建议和常见问题解答,希望能帮助您更好地理解和应用这一技术。Transformer和GPT无疑在推动NLP技术发展方面发挥了重要作用,未来也必将继续带来更多创新和惊喜。
如果您有任何问题或想深入了解某个具体方面,欢迎留言讨论。期待您的参与和分享!